Fix async #162
There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -28,10 +28,11 @@ def __init__(self, args): | |
| Aggregator.__init__(self, args) | ||
| self.resource_manager = ResourceManager(self.experiment_mode) | ||
| self.async_buffer_size = args.async_buffer | ||
| self.max_concurrency = args.max_concurrency | ||
| self.client_round_duration = {} | ||
| self.client_start_time = collections.defaultdict(list) | ||
| self.round_stamp = [0] | ||
| self.client_model_version = collections.defaultdict(list) | ||
| self.virtual_client_clock = {} | ||
| self.weight_tensor_type = {} | ||
|
|
||
|
|
@@ -40,6 +41,8 @@ def __init__(self, args): | |
| self.aggregate_update = {} | ||
| self.importance_sum = 0 | ||
| self.client_end = [] | ||
| self.round_staleness = [] | ||
| self.model_concurrency = collections.defaultdict(int) | ||
|
|
||
| def tictak_client_tasks(self, sampled_clients, num_clients_to_collect): | ||
|
|
||
|
|
@@ -108,8 +111,10 @@ def aggregate_client_weights(self, results): | |
| """ | ||
| # Start to take the average of updates, and we do not keep updates to save memory | ||
| # Importance of each update is 1/staleness | ||
| client_staleness = self.round - self.client_model_version[results['clientId']].pop(0) | ||
|
|
||
| importance = 1./(math.sqrt(1 + client_staleness)) | ||
| self.round_staleness.append(client_staleness) | ||
|
|
||
| new_round_aggregation = (self.model_in_update == 1) | ||
| if new_round_aggregation: | ||
|
|
@@ -134,25 +139,21 @@ def aggregate_client_weights(self, results): | |
| self.aggregate_update[p] = param_weight * importance | ||
| else: | ||
| self.aggregate_update[p] += param_weight * importance | ||
|
|
||
| if self.model_in_update == self.async_buffer_size: | ||
| for p in self.model_weights: | ||
| d_type = self.weight_tensor_type[p] | ||
| self.model_weights[p].data = ( | ||
| self.model_weights[p].data + self.aggregate_update[p] / float(self.importance_sum) # self.model_in_update | ||
| ).to(dtype=d_type) | ||
|
|
||
| def round_completion_handler(self): | ||
| self.round += 1 | ||
|
|
||
| logging.info(f"Round {self.round} average staleness {np.mean(self.round_staleness)}") | ||
| self.round_staleness = [] | ||
| self.global_virtual_clock = self.round_stamp[-1] | ||
|
|
||
| if self.round % self.args.decay_round == 0: | ||
| self.args.learning_rate = max( | ||
| self.args.learning_rate * self.args.decay_factor, self.args.min_learning_rate) | ||
|
|
@@ -172,10 +173,10 @@ def round_completion_handler(self): | |
|
|
||
| # update select participants | ||
| # NOTE: we simulate async, while have to sync every 20 rounds to avoid large division to trace | ||
| if self.resource_manager.get_task_length() < self.async_buffer_size: | ||
|
|
||
| self.sampled_participants = self.select_participants( | ||
| select_num_participants=self.async_buffer_size*5, overcommitment=self.args.overcommitment) | ||
| (clientsToRun, clientsStartTime, virtual_client_clock) = self.tictak_client_tasks( | ||
| self.sampled_participants, len(self.sampled_participants)) | ||
|
|
||
|
|
@@ -253,21 +254,30 @@ def get_client_conf(self, clientId): | |
| def create_client_task(self, executorId): | ||
| """Issue a new client training task to the executor""" | ||
|
|
||
| train_config = None | ||
| model = None | ||
| while True: | ||
| next_clientId = self.resource_manager.get_next_task(executorId) | ||
| if next_clientId != None: | ||
| config = self.get_client_conf(next_clientId) | ||
| start_time = self.client_start_time[next_clientId][0] | ||
| end_time = self.client_round_duration[next_clientId] + start_time | ||
| model_id = self.find_latest_model(start_time) | ||
| if end_time < self.round_stamp[-1] or self.model_concurrency[model_id] > self.max_concurrency + self.async_buffer_size: | ||
| self.client_start_time[next_clientId].pop(0) | ||
| continue | ||
|
|
||
| self.client_model_version[next_clientId].append(model_id) | ||
|
|
||
| # The executor has already received the model, thus transferring id is enough | ||
| model = model_id | ||
| train_config = {'client_id': next_clientId, 'task_config': config, 'end_time': end_time} | ||
| logging.info( | ||
| f"Client {next_clientId} train on model {model_id} during {int(start_time)}-{int(end_time)}") | ||
| self.model_concurrency[model_id] += 1 | ||
| break | ||
| else: | ||
| break | ||
|
|
||
| return train_config, model | ||
|
|
||
|
|
@@ -290,11 +300,17 @@ def client_completion_handler(self, results): | |
| # Format: | ||
| # -results = {'clientId':clientId, 'update_weight': model_param, 'moving_loss': round_train_loss, | ||
| # 'trained_size': count, 'wall_duration': time_cost, 'success': is_success 'utility': utility} | ||
|
|
||
| # [Async] some clients are scheduled earlier, which should be aggregated in previous round but receive the result late | ||
|
Contributor
There was a problem hiding this comment. For my understanding: why do we want to ignore clients that should be aggregated in previous rounds? Don't we want to aggregate it anyways with a staleness factor?
Collaborator
There was a problem hiding this comment. Yea, that's also a solution🤔, if we ignore the fact that the supposed
Collaborator
Author
There was a problem hiding this comment. I think we can aggregate it according to the staleness factor for now. |
||
| if self.client_round_duration[results['clientId']] + self.client_start_time[results['clientId']][0] < self.round_stamp[-1]: | ||
| # Ignore tasks that are issued earlier but finish late | ||
| self.client_start_time[results['clientId']].pop(0) | ||
| logging.info(f"Warning: Ignore late-response client {results['clientId']}") | ||
| return | ||
| if self.round - self.client_model_version[results['clientId']][0] > self.args.max_staleness: | ||
| logging.info(f"Warning: Ignore stale client {results['clientId']} with {self.round - self.client_model_version[results['clientId']][0]}") | ||
| self.client_model_version[results['clientId']].pop(0) | ||
| return | ||
|
|
||
| # [ASYNC] New checkin clients ID would overlap with previous unfinished clients | ||
| logging.info(f"Client {results['clientId']} completes from {self.client_start_time[results['clientId']][0]} to {self.client_start_time[results['clientId']][0]+self.client_round_duration[results['clientId']]}") | ||
|
|
@@ -340,7 +356,6 @@ def CLIENT_EXECUTE_COMPLETION(self, request, context): | |
| executor_id, client_id, event = request.executor_id, request.client_id, request.event | ||
| execution_status, execution_msg = request.status, request.msg | ||
| meta_result, data_result = request.meta_result, request.data_result | ||
|
|
||
| if event == commons.CLIENT_TRAIN: | ||
| # Training results may be uploaded in CLIENT_EXECUTE_RESULT request later, | ||
|
|
@@ -396,7 +411,7 @@ def event_monitor(self): | |
| clientID = self.deserialize_response(data)['clientId'] | ||
| logging.info( | ||
| f"last client {clientID} at round {self.round} ") | ||
| # [ASYNC] handle different completion order | ||
| self.round_stamp.append(max(self.client_end)) | ||
| self.client_end = [] | ||
| self.round_completion_handler() | ||
|
|
||
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Oops, something went wrong.
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
In this async aggregator implementation, is there a notion of concurrency? In the PAPAYA paper, concurrency is a hyper-parameter in addition to the buffer size.
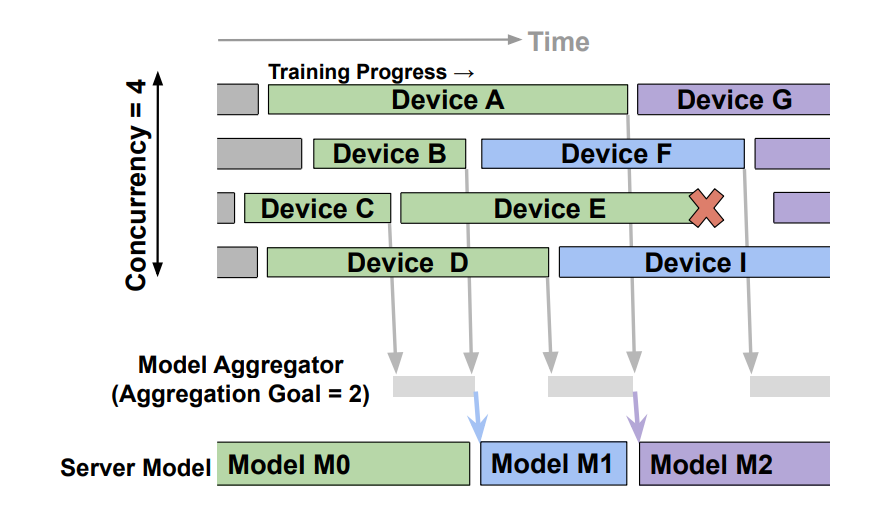
Uh oh!
There was an error while loading. Please reload this page.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
That's a good point and sorry for not combining Papaya's design. We should do 2 more things
tictak_client_tasks, the number of overlapping tasks doesn't exceed max_concurrency